最强开源大模型Llama 3来了,4000亿参数狙击GPT-4,训练数据达Llama 2七倍
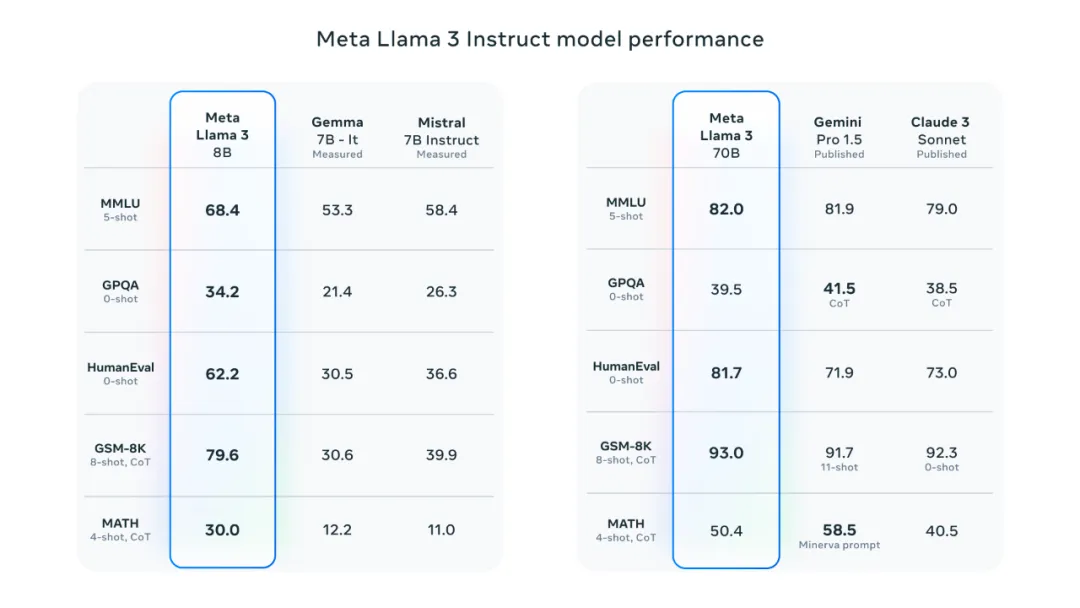
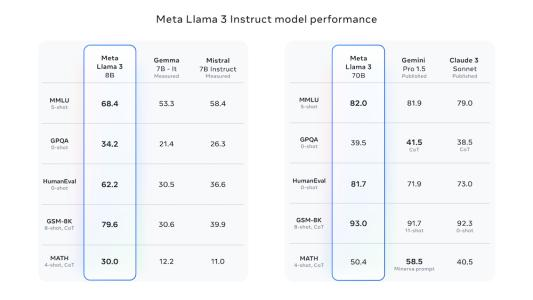
最强开源大模型Llama 3来了,4000亿参数狙击GPT-4,训练数据达Llama 2七倍智东西4月19日消息,Meta推出迄今为止能力最强的开源大模型Llama 3系列,发布8B和70B两个版本。 Llama 3在一众榜单中取得开源SOTA(当前最优效果)。Llama 3 8B在MMLU、GPQA、HumanEval、GSM-8K等多项基准上超过谷歌Gemma 7B和Mistral 7B Instruct。
来自主题: AI技术研报
9587 点击 2024-04-20 12:10